Go语言设计与实现
- https://golang.org/ref/spec
- Go 语言设计与实现
- teh-cmc/go-internals: A book about the internals of the Go programming language.
- 深入浅出 Golang Runtime 2019.08.ppt

编译原理
抽象语法树(AST):语义分析、类型检查
静态单赋值(Static Single Assigment,SSA):每个变量只会被赋值一次。实现一些优化:
- 常数传播
- 值域传播
- 稀疏有条件的常数传播
- 消除无用的代码
- 全域数值编号
- 消除部分的冗余
- 寄存器分配
指令集
uname -m可获得x86是常见的指令集- 复杂指令集计算机(CISC)
- 精简指令集计算机(RISC)
编译器
- Go的编译器源码在
src/cmd/compile目录里 - 分为前端和后端
- 前端:词法分析、语法分析、类型检查、中间代码生成
- 后端:目标代码的生成
- 过程:lexical analysis -> syntax analysis -> semantic analysis -> IR generation -> code optimization -> machinecode geenration
- 分四阶段
- 词语和语法分析:token、语法解析器是LALR(1)的文法
- 类型检查和AST转换
make关键字会被替换成 makeslice, makechan 等函数
- 通用SSA生成
- 类型检查之后,通过
compileFunctions函数对全部函数进行编译,会在一个队列里发送给几个后端协程消费并转换成中间代码
- 类型检查之后,通过
- 最后机器码生成
src/cmd/compile/internal目录包含很多机器码生成相关的包- 支持WebAssembly
关键字
for, range
- array, slice
- string
- map
- channel
select
select 是一种与 switch 相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式必须都是 channel 的收发操作。

defer

panic, recover

make, new
make 关键字的作用是创建切片、哈希表和 Channel 等内置的数据结构,而 new 的作用是为类型申请一片内存空间,并返回指向这片内存的指针。
基础知识
数据结构
- 数组
- 分为线型数组、多维数组
[...]T数组大小自动推断,这种声明格式称作DDDArray- 元素数量小于等于4个时,元素放置在栈上;大于4个放置到静态区
- Go 语言运行时在发现数组、切片和字符串的越界操作会由运行时的
panicIndex和runtime.goPanicIndex函数触发程序的运行时错误并导致崩溃退出 - 编译时Go为数组的访问做了上限的判断,不满足触发
PanicBounds指令,不能判断的放到运行时进行判断(通过插入panicIndex进行判断)
- 切片
- 长度是动态的,声明只需要指定切片中的元素类型
- 初始化方式
arr[0:3][]int{1, 2, 3}make([]int, 10)make([]int, 10, 20)mallocgc是用于申请内存的函数。如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的一些对象会在堆上初始化。- 之前的版本中,数组指针、长度、容量会被合成一个
slice结构并返回,2018年10月之后构建结构体SliceHeader的工作就都交给runtime.makeslice的调用方处理了。调用方会在编译期间构建切片结构体。
- 元素访问的
len和cap操作,即OLEN和OCAP,会在SSA生成阶段被转换成OpSliceLen和OpSliceCap操作。另外还有OINDEX操作会在中间代码生成期间转换成对地址的直接访问。 - 追加使用的
append关键字。根据返回值是否赋值回原变量,使用两种处理流程;是的话,会直接把长度、容量赋值给原指针。容量不够时会扩容,根据切片大小采用不同的扩容策略;计算新容量发生溢出或者内存超过上限时会panic。 - 切片的拷贝使用
copy函数,分为编译时和运行时。编译时会使用memmove对内存进行拷贝,否则会使用runtime.slicecopy函数替换运行时调用的copy。使用memmove对整块内存进行拷贝,和依次对元素进行拷贝相比,能够提供更好的性能;但还是会占用非常多的资源。
- 哈希表
- 哈希函数的选择在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键映射到不同的索引上,这要求哈希函数输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的结果是不可能实现的。
- 比较实际的方式是让哈希函数的结果能够尽可能的均匀分布,然后通过工程上的手段解决哈希碰撞的问题,但是哈希的结果一定要尽可能均匀,结果不均匀的哈希函数会造成更多的冲突并导致更差的读写性能。
- 解决碰撞问题,有开放寻址法和拉链法。(略)
hmap结构体有存储了哈希表的元素数量,当前持有的buckets数量(的对数),创建哈希表示引入随机性的种子,扩容时保存之前buckets的字段,大小是当前buckets的一半。桶结构是bmap,每个能存储8个键值对。当单个桶无法装满时就会使用extra.overflow中桶存储溢出的数据。两种桶在内存中是连续存储的,后续成为正常桶和溢出桶。创建过多的溢出桶会导致哈希表的扩容。- 初始化
- 字面量方式
map[string]int{"1": 2}- 最终调用
cmd/compile/internal/gc.maplit来初始化- 最元素个数小于等于25个时,使用
make(map[string]int, 3)的方式初始化,再逐个添加 - 超过25个,会创建两个数组分别存储键和值,再逐个添加
- 最元素个数小于等于25个时,使用
- 用
make创建哈希,Go会在类型检查期间将他们转换成对runtime.makemap的调用
- 最终调用
- 字面量方式
- 读写操作
- 采用下标读取、写入
- 会被转换成对哈希的
OINDEXMAP操作
- 会被转换成对哈希的
delete(hash, key)range- 运行时函数
runtime.mapaccess1,runtime.mapaccess2runtime.mapassignruntime.growWork
runtime.hashGrowruntime.evacuate:哈希表的数据迁移runtime.advanceEvacuationMark增加哈希的nevacuate计数器
runtime.mapdeleteruntime.growWork
- 随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
- 采用下标读取、写入
- 字符串
string在C里实际上是char[]类型,也就是Go里的[]byte类型,在Go的编译期间会被通过SRODATA标记成只读数据- 拼接
+号会将对应的OADD节点转换成OADDSTR类型的节点,最后会调用runtime.concatstrings,运行时调用copy将输入的多个字符串拷贝到目标字符串所在的空间
- 类型转换
runtime.slicebytetostring:从字节数组到字符串runtime.stringStructOf会将传入的字符串指针转换成stringStruct结构体指针,并设置字符串指针str和长度len,然后通过memmove复制原来的字节数组
runtime.stringtoslicebyte- 可能调用
runtime.rawbyteslice创建一个新的字节切片
- 可能调用
语言特性
函数调用
C 语言和 Go 语言在设计函数的调用惯例时选择也不同的实现。C 语言同时使用寄存器和栈传递参数,使用 eax 寄存器传递返回值;而 Go 语言使用栈传递参数和返回值。我们可以对比一下这两种设计的优点和缺点:
- C 语言的方式能够极大地减少函数调用的额外开销,但是也增加了实现的复杂度;
- CPU 访问栈的开销比访问寄存器高几十倍3;
- 需要单独处理函数参数过多的情况;
- Go 语言的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能;
- 不需要考虑超过寄存器数量的参数应该如何传递;
- 不需要考虑不同架构上的寄存器差异;
- 函数入参和出参的内存空间需要在栈上进行分配;
Go 语言使用栈作为参数和返回值传递的方法是综合考虑后的设计,选择这种设计意味着编译器会更加简单、更容易维护。
参数传递
Go语言在传递参数时是传值还是传引用?不同语言会选择不同的方式传递参数,Go 语言选择了传值的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。
接口
Go 语言中的接口就是一组方法的签名,它是 Go 语言的重要组成部分。使用接口能够让我们更好地组织并写出易于测试的代码,然而很多工程师对 Go 的接口了解都非常有限,也不清楚其底层的实现原理,这成为了开发高性能服务的最大阻碍。
接口的实现
Go 语言中接口的实现都是隐式的。在 Java 中实现接口需要显式的声明接口并实现所有方法;在 Go 中实现接口的所有方法就隐式的实现了接口。
接口也是 Go 语言中的一种类型,它能够出现在变量的定义、函数的入参和返回值中并对它们进行约束,不过 Go 语言中有两种略微不同的接口,一种是带有一组方法的接口,另一种是不带任何方法的 interface{}。使用 iface 结构体表示第一种接口,使用 eface 结构体表示第二种空接口,两种接口虽然都使用 interface 声明,但是由于后者在 Go 语言中非常常见,所以在实现时使用了特殊的类型。
接口实现的接受者类型和传值类型
结构体类型和指针类型是完全不同的,就像我们不能向一个接受指针的函数传递结构体,在实现接口时这两种类型也不能划等号。

由于函数调用是传的复制值,结构体指针实现的接口,而传过去一个结构体的复制的话,是不能通过编译的;反过来,结构体实现的接口,而传过去一个指针的复制,是可以解引用到同一个原始结构体的。
当然这并不意味着我们应该一律使用结构体实现接口,这个问题在实际工程中也没那么重要。
接口类型不是任意类型
空指针nil是带有类型的,即指向的对象的类型;在传参时可能发生隐式的类型转换,变成另外一种类型,不再与nil字面值相等(==)。只有 nil 所指向的类型是 *T 时,它本身的类型才是 <nil>,才会与字面值 nil 相等。
type IntArr []int
func fn1(z *IntArr) bool {
return z == nil
}
func fn2(z interface{}) bool {
return z == nil
}
func main() {
var x []int
var y IntArr
var z *IntArr
fmt.Printf("%v %T\n", nil, nil) // <nil> <nil>
fmt.Printf("%v %T\n", x, x) // [] []int
fmt.Printf("%v %T\n", y, y) // [] main.IntArr
fmt.Printf("%v %T\n", z, z) // nil *main.IntArr
fmt.Println(reflect.TypeOf(nil), reflect.TypeOf(x), reflect.TypeOf(y), reflect.TypeOf(z)) // <nil> []int main.IntArr *main.IntArr
fmt.Println(x == nil) // true
fmt.Println(y == nil) // true
fmt.Println(z == nil) // true
fmt.Println("fn1", fn1(&y)) // false
fmt.Println("fn2", fn2(y)) // false
fmt.Println("fn2", fn2(&y)) // false
fmt.Println("fn1", fn1(z)) // true
fmt.Println("fn2", fn2(z)) // false
fmt.Println("fn2", fn2(&z)) // false
}
空接口(eface)
空接口用interface{}表示,任何一个值都可以转换成空接口,本身是一个结构体,里面包含了转换前的值的类型和地址指针。
type eface struct { // 16 bytes
_type *_type
data unsafe.Pointer
}
type iface struct { // 16 bytes
tab *itab
data unsafe.Pointer
}
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}
type itab struct { // 32 bytes
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
从测试结果可以看到,使用结构体来实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口。
使用结构体带来的巨大性能差异不只是接口带来的问题,带来性能问题主要因为 Go 语言在函数调用时是传值的,动态派发的过程只是放大了参数拷贝带来的影响。
反射
反射是 Go 语言比较重要的特性。虽然在大多数的应用和服务中并不常见,但是很多框架都依赖 Go 语言的反射机制实现简化代码的逻辑。因为 Go 语言的语法元素很少、设计简单,所以它没有特别强的表达能力,但是 Go 语言的 reflect 包能够弥补它在语法上的一些劣势。
reflect 实现了运行时的反射能力,能够让程序操作不同类型的对象。反射包中有两对非常重要的函数和类型,reflect.TypeOf 能获取类型信息,reflect.ValueOf 能获取数据的运行时表示,另外两个类型是 Type 和 Value,它们与函数是一一对应的关系。
type Type interface {
Align() int
FieldAlign() int
Method(int) Method
MethodByName(string) (Method, bool)
NumMethod() int
Kind() Kind
...
Implements(u Type) bool
...
}
type Value struct {
// contains filtered or unexported fields
}
func (v Value) Addr() Value
func (v Value) Bool() bool
func (v Value) Bytes() []byte
更多的内部构造:
// emptyInterface is the header for an interface{} value.
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
// nonEmptyInterface is the header for an interface value with methods.
type nonEmptyInterface struct {
// see ../runtime/iface.go:/Itab
itab *struct {
ityp *rtype // static interface type
typ *rtype // dynamic concrete type
hash uint32 // copy of typ.hash
_ [4]byte
fun [100000]unsafe.Pointer // method table
}
word unsafe.Pointer
}
// rtype is the common implementation of most values.
// It is embedded in other struct types.
//
// rtype must be kept in sync with ../runtime/type.go:/^type._type.
type rtype struct {
size uintptr
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
alg *typeAlg // algorithm table
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
func (t *rtype) String() string {
s := t.nameOff(t.str).name()
if t.tflag&tflagExtraStar != 0 {
return s[1:]
}
return s
}
type nameOff int32 // offset to a name
type typeOff int32 // offset to an *rtype
type textOff int32 // offset from top of text section
// See more in [unsafe.Pointer](https://godoc.org/unsafe#Pointer) for unsafe.Pointer
func (t *rtype) nameOff(off nameOff) name {
return name{(*byte)(resolveNameOff(unsafe.Pointer(t), int32(off)))}
}
func (t *rtype) typeOff(off typeOff) *rtype {
return (*rtype)(resolveTypeOff(unsafe.Pointer(t), int32(off)))
}
func (t *rtype) textOff(off textOff) unsafe.Pointer {
return resolveTextOff(unsafe.Pointer(t), int32(off))
}
// resolveNameOff resolves a name offset from a base pointer.
// The (*rtype).nameOff method is a convenience wrapper for this function.
// Implemented in the runtime package.
func resolveNameOff(ptrInModule unsafe.Pointer, off int32) unsafe.Pointer
// resolveTypeOff resolves an *rtype offset from a base type.
// The (*rtype).typeOff method is a convenience wrapper for this function.
// Implemented in the runtime package.
func resolveTypeOff(rtype unsafe.Pointer, off int32) unsafe.Pointer
// resolveTextOff resolves an function pointer offset from a base type.
// The (*rtype).textOff method is a convenience wrapper for this function.
// Implemented in the runtime package.
func resolveTextOff(rtype unsafe.Pointer, off int32) unsafe.Pointer
// Type is the representation of a Go type.
//
// Not all methods apply to all kinds of types. Restrictions,
// if any, are noted in the documentation for each method.
// Use the Kind method to find out the kind of type before
// calling kind-specific methods. Calling a method
// inappropriate to the kind of type causes a run-time panic.
//
// Type values are comparable, such as with the == operator,
// so they can be used as map keys.
// Two Type values are equal if they represent identical types.
type Type interface {
// Methods applicable to all types.
// Align returns the alignment in bytes of a value of
// this type when allocated in memory.
Align() int
// FieldAlign returns the alignment in bytes of a value of
// this type when used as a field in a struct.
FieldAlign() int
// Method returns the i'th method in the type's method set.
// It panics if i is not in the range [0, NumMethod()).
//
// For a non-interface type T or *T, the returned Method's Type and Func
// fields describe a function whose first argument is the receiver.
//
// For an interface type, the returned Method's Type field gives the
// method signature, without a receiver, and the Func field is nil.
//
// Only exported methods are accessible and they are sorted in
// lexicographic order.
Method(int) Method
// MethodByName returns the method with that name in the type's
// method set and a boolean indicating if the method was found.
//
// For a non-interface type T or *T, the returned Method's Type and Func
// fields describe a function whose first argument is the receiver.
//
// For an interface type, the returned Method's Type field gives the
// method signature, without a receiver, and the Func field is nil.
MethodByName(string) (Method, bool)
// NumMethod returns the number of exported methods in the type's method set.
NumMethod() int
// Name returns the type's name within its package for a defined type.
// For other (non-defined) types it returns the empty string.
Name() string
// PkgPath returns a defined type's package path, that is, the import path
// that uniquely identifies the package, such as "encoding/base64".
// If the type was predeclared (string, error) or not defined (*T, struct{},
// []int, or A where A is an alias for a non-defined type), the package path
// will be the empty string.
PkgPath() string
// Size returns the number of bytes needed to store
// a value of the given type; it is analogous to unsafe.Sizeof.
Size() uintptr
// String returns a string representation of the type.
// The string representation may use shortened package names
// (e.g., base64 instead of "encoding/base64") and is not
// guaranteed to be unique among types. To test for type identity,
// compare the Types directly.
String() string
// Kind returns the specific kind of this type.
Kind() Kind
// Implements reports whether the type implements the interface type u.
Implements(u Type) bool
// AssignableTo reports whether a value of the type is assignable to type u.
AssignableTo(u Type) bool
// ConvertibleTo reports whether a value of the type is convertible to type u.
ConvertibleTo(u Type) bool
// Comparable reports whether values of this type are comparable.
Comparable() bool
// Methods applicable only to some types, depending on Kind.
// The methods allowed for each kind are:
//
// Int*, Uint*, Float*, Complex*: Bits
// Array: Elem, Len
// Chan: ChanDir, Elem
// Func: In, NumIn, Out, NumOut, IsVariadic.
// Map: Key, Elem
// Ptr: Elem
// Slice: Elem
// Struct: Field, FieldByIndex, FieldByName, FieldByNameFunc, NumField
// Bits returns the size of the type in bits.
// It panics if the type's Kind is not one of the
// sized or unsized Int, Uint, Float, or Complex kinds.
Bits() int
// ChanDir returns a channel type's direction.
// It panics if the type's Kind is not Chan.
ChanDir() ChanDir
// IsVariadic reports whether a function type's final input parameter
// is a "..." parameter. If so, t.In(t.NumIn() - 1) returns the parameter's
// implicit actual type []T.
//
// For concreteness, if t represents func(x int, y ... float64), then
//
// t.NumIn() == 2
// t.In(0) is the reflect.Type for "int"
// t.In(1) is the reflect.Type for "[]float64"
// t.IsVariadic() == true
//
// IsVariadic panics if the type's Kind is not Func.
IsVariadic() bool
// Elem returns a type's element type.
// It panics if the type's Kind is not Array, Chan, Map, Ptr, or Slice.
Elem() Type
// Field returns a struct type's i'th field.
// It panics if the type's Kind is not Struct.
// It panics if i is not in the range [0, NumField()).
Field(i int) StructField
// FieldByIndex returns the nested field corresponding
// to the index sequence. It is equivalent to calling Field
// successively for each index i.
// It panics if the type's Kind is not Struct.
FieldByIndex(index []int) StructField
// FieldByName returns the struct field with the given name
// and a boolean indicating if the field was found.
FieldByName(name string) (StructField, bool)
// FieldByNameFunc returns the struct field with a name
// that satisfies the match function and a boolean indicating if
// the field was found.
//
// FieldByNameFunc considers the fields in the struct itself
// and then the fields in any embedded structs, in breadth first order,
// stopping at the shallowest nesting depth containing one or more
// fields satisfying the match function. If multiple fields at that depth
// satisfy the match function, they cancel each other
// and FieldByNameFunc returns no match.
// This behavior mirrors Go's handling of name lookup in
// structs containing embedded fields.
FieldByNameFunc(match func(string) bool) (StructField, bool)
// In returns the type of a function type's i'th input parameter.
// It panics if the type's Kind is not Func.
// It panics if i is not in the range [0, NumIn()).
In(i int) Type
// Key returns a map type's key type.
// It panics if the type's Kind is not Map.
Key() Type
// Len returns an array type's length.
// It panics if the type's Kind is not Array.
Len() int
// NumField returns a struct type's field count.
// It panics if the type's Kind is not Struct.
NumField() int
// NumIn returns a function type's input parameter count.
// It panics if the type's Kind is not Func.
NumIn() int
// NumOut returns a function type's output parameter count.
// It panics if the type's Kind is not Func.
NumOut() int
// Out returns the type of a function type's i'th output parameter.
// It panics if the type's Kind is not Func.
// It panics if i is not in the range [0, NumOut()).
Out(i int) Type
common() *rtype
uncommon() *uncommonType
}
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero Value.
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
// TODO: Maybe allow contents of a Value to live on the stack.
// For now we make the contents always escape to the heap. It
// makes life easier in a few places (see chanrecv/mapassign
// comment below).
escapes(i)
return unpackEface(i)
}
// Value is the reflection interface to a Go value.
//
// Not all methods apply to all kinds of values. Restrictions,
// if any, are noted in the documentation for each method.
// Use the Kind method to find out the kind of value before
// calling kind-specific methods. Calling a method
// inappropriate to the kind of type causes a run time panic.
//
// The zero Value represents no value.
// Its IsValid method returns false, its Kind method returns Invalid,
// its String method returns "<invalid Value>", and all other methods panic.
// Most functions and methods never return an invalid value.
// If one does, its documentation states the conditions explicitly.
//
// A Value can be used concurrently by multiple goroutines provided that
// the underlying Go value can be used concurrently for the equivalent
// direct operations.
//
// To compare two Values, compare the results of the Interface method.
// Using == on two Values does not compare the underlying values
// they represent.
type Value struct {
// typ holds the type of the value represented by a Value.
typ *rtype
// Pointer-valued data or, if flagIndir is set, pointer to data.
// Valid when either flagIndir is set or typ.pointers() is true.
ptr unsafe.Pointer
// flag holds metadata about the value.
// The lowest bits are flag bits:
// - flagStickyRO: obtained via unexported not embedded field, so read-only
// - flagEmbedRO: obtained via unexported embedded field, so read-only
// - flagIndir: val holds a pointer to the data
// - flagAddr: v.CanAddr is true (implies flagIndir)
// - flagMethod: v is a method value.
// The next five bits give the Kind of the value.
// This repeats typ.Kind() except for method values.
// The remaining 23+ bits give a method number for method values.
// If flag.kind() != Func, code can assume that flagMethod is unset.
// If ifaceIndir(typ), code can assume that flagIndir is set.
flag
// A method value represents a curried method invocation
// like r.Read for some receiver r. The typ+val+flag bits describe
// the receiver r, but the flag's Kind bits say Func (methods are
// functions), and the top bits of the flag give the method number
// in r's type's method table.
}
// String returns the string v's underlying value, as a string.
// String is a special case because of Go's String method convention.
// Unlike the other getters, it does not panic if v's Kind is not String.
// Instead, it returns a string of the form "<T value>" where T is v's type.
// The fmt package treats Values specially. It does not call their String
// method implicitly but instead prints the concrete values they hold.
func (v Value) String() string {
switch k := v.kind(); k {
case Invalid:
return "<invalid Value>"
case String:
return *(*string)(v.ptr)
}
// If you call String on a reflect.Value of other type, it's better to
// print something than to panic. Useful in debugging.
return "<" + v.Type().String() + " Value>"
}
type flag uintptr
const (
flagKindWidth = 5 // there are 27 kinds
flagKindMask flag = 1<<flagKindWidth - 1
flagStickyRO flag = 1 << 5
flagEmbedRO flag = 1 << 6
flagIndir flag = 1 << 7
flagAddr flag = 1 << 8
flagMethod flag = 1 << 9
flagMethodShift = 10
flagRO flag = flagStickyRO | flagEmbedRO
)
func (f flag) kind() Kind {
return Kind(f & flagKindMask)
}
// Interface returns v's current value as an interface{}.
// It is equivalent to:
// var i interface{} = (v's underlying value)
// It panics if the Value was obtained by accessing
// unexported struct fields.
func (v Value) Interface() (i interface{}) {
return valueInterface(v, true)
}
func valueInterface(v Value, safe bool) interface{} {
if v.flag == 0 {
panic(&ValueError{"reflect.Value.Interface", Invalid})
}
if safe && v.flag&flagRO != 0 {
// Do not allow access to unexported values via Interface,
// because they might be pointers that should not be
// writable or methods or function that should not be callable.
panic("reflect.Value.Interface: cannot return value obtained from unexported field or method")
}
if v.flag&flagMethod != 0 {
v = makeMethodValue("Interface", v)
}
if v.kind() == Interface {
// Special case: return the element inside the interface.
// Empty interface has one layout, all interfaces with
// methods have a second layout.
if v.NumMethod() == 0 {
return *(*interface{})(v.ptr)
}
return *(*interface {
M()
})(v.ptr)
}
// TODO: pass safe to packEface so we don't need to copy if safe==true?
return packEface(v)
}
// packEface converts v to the empty interface.
func packEface(v Value) interface{} {}
// unpackEface converts the empty interface i to a Value.
func unpackEface(i interface{}) Value {}
// A Kind represents the specific kind of type that a Type represents.
// The zero Kind is not a valid kind.
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
// String returns the name of k.
func (k Kind) String() string {
if int(k) < len(kindNames) {
return kindNames[k]
}
return "kind" + strconv.Itoa(int(k))
}
func (t *rtype) Implements(u Type) bool {
if u == nil {
panic("reflect: nil type passed to Type.Implements")
}
if u.Kind() != Interface {
panic("reflect: non-interface type passed to Type.Implements")
}
return implements(u.(*rtype), t)
}
// reflect.TypeOf(CustomError{}).Implements(typeOfError)
var kindNames = []string{
Invalid: "invalid",
Bool: "bool",
Int: "int",
Int8: "int8",
Int16: "int16",
Int32: "int32",
Int64: "int64",
Uint: "uint",
Uint8: "uint8",
Uint16: "uint16",
Uint32: "uint32",
Uint64: "uint64",
Uintptr: "uintptr",
Float32: "float32",
Float64: "float64",
Complex64: "complex64",
Complex128: "complex128",
Array: "array",
Chan: "chan",
Func: "func",
Interface: "interface",
Map: "map",
Ptr: "ptr",
Slice: "slice",
String: "string",
Struct: "struct",
UnsafePointer: "unsafe.Pointer",
}
// Method represents a single method.
type Method struct {
// Name is the method name.
// PkgPath is the package path that qualifies a lower case (unexported)
// method name. It is empty for upper case (exported) method names.
// The combination of PkgPath and Name uniquely identifies a method
// in a method set.
// See https://golang.org/ref/spec#Uniqueness_of_identifiers
Name string
PkgPath string
Type Type // method type
Func Value // func with receiver as first argument
Index int // index for Type.Method
}
运行时反射是程序在运行期间检查其自身结构的一种方式。反射带来的灵活性是一把双刃剑,反射作为一种元编程方式可以减少重复代码,但是过量的使用反射会使我们的程序逻辑变得难以理解并且运行缓慢。我们在这一节中会介绍 Go 语言反射的三大法则,其中包括:
- 从
interface{}变量可以反射出反射对象;reflect.TypeOfreflect.ValueOf
- 从反射对象可以获取
interface{}变量;reflect.Value.Interface:reflect.ValueOf(1).Interface().(int)
- 要修改反射对象,其值必须可设置;
- 不行:
reflect.ValueOf(1).SetInt(10) - 可行:
reflect.Valueof(&1).Elem().SetInt(10)
- 不行:

几个概念
- settable (assginable):addressable + not read-only (
flagRO). Settability is a bit like addressability, but stricter. It’s the property that a reflection object can modify the actual storage that was used to create the reflection object. Settability is determined by whether the reflection object holds the original item. - addressable:
flagAddr,指可以通过&a操作取得变量地址 - exported: unexported fiedls are read-only
type Value struct {
// flag holds metadata about the value.
// The lowest bits are flag bits:
// - flagStickyRO: obtained via unexported not embedded field, so read-only
// - flagEmbedRO: obtained via unexported embedded field, so read-only
// - flagIndir: val holds a pointer to the data
// - flagAddr: v.CanAddr is true (implies flagIndir)
// - flagMethod: v is a method value.
// The next five bits give the Kind of the value.
// This repeats typ.Kind() except for method values.
// The remaining 23+ bits give a method number for method values.
// If flag.kind() != Func, code can assume that flagMethod is unset.
// If ifaceIndir(typ), code can assume that flagIndir is set.
flag
}
// CanAddr reports whether the value's address can be obtained with Addr.
// Such values are called addressable. A value is addressable if it is
// an element of a slice, an element of an addressable array,
// a field of an addressable struct, or the result of dereferencing a pointer.
// If CanAddr returns false, calling Addr will panic.
func (v Value) CanAddr() bool {
return v.flag&flagAddr != 0
}
// CanSet reports whether the value of v can be changed.
// A Value can be changed only if it is addressable and was not
// obtained by the use of unexported struct fields.
// If CanSet returns false, calling Set or any type-specific
// setter (e.g., SetBool, SetInt) will panic.
func (v Value) CanSet() bool {
return v.flag&(flagAddr|flagRO) == flagAddr
}
// Elem returns the value that the interface v contains
// or that the pointer v points to.
// It panics if v's Kind is not Interface or Ptr.
// It returns the zero Value if v is nil.
func (v Value) Elem() Value {
k := v.kind()
switch k {
case Interface:
var eface interface{}
if v.typ.NumMethod() == 0 {
eface = *(*interface{})(v.ptr)
} else {
eface = (interface{})(*(*interface {
M()
})(v.ptr))
}
x := unpackEface(eface)
if x.flag != 0 {
x.flag |= v.flag.ro()
}
return x
case Ptr:
ptr := v.ptr
if v.flag&flagIndir != 0 {
ptr = *(*unsafe.Pointer)(ptr)
}
// The returned value's address is v's value.
if ptr == nil {
return Value{}
}
tt := (*ptrType)(unsafe.Pointer(v.typ))
typ := tt.elem
fl := v.flag&flagRO | flagIndir | flagAddr
fl |= flag(typ.Kind())
return Value{typ, ptr, fl}
}
panic(&ValueError{"reflect.Value.Elem", v.kind()})
}
const flagRO flag = flagStickyRO | flagEmbedRO
// mustBeAssignable panics if f records that the value is not assignable,
// which is to say that either it was obtained using an unexported field
// or it is not addressable.
func (f flag) mustBeAssignable() {
if f&flagRO != 0 || f&flagAddr == 0 {
f.mustBeAssignableSlow()
}
}
func (f flag) mustBeAssignableSlow() {
if f == 0 {
panic(&ValueError{methodName(), Invalid})
}
// Assignable if addressable and not read-only.
if f&flagRO != 0 {
panic("reflect: " + methodName() + " using value obtained using unexported field")
}
if f&flagAddr == 0 {
panic("reflect: " + methodName() + " using unaddressable value")
}
}
// mustBeExported panics if f records that the value was obtained using
// an unexported field.
func (f flag) mustBeExported() {
if f == 0 || f&flagRO != 0 {
f.mustBeExportedSlow()
}
}
func (f flag) mustBeExportedSlow() {
if f == 0 {
panic(&ValueError{methodName(), Invalid})
}
if f&flagRO != 0 {
panic("reflect: " + methodName() + " using value obtained using unexported field")
}
}
// ifaceIndir reports whether t is stored indirectly in an interface value.
func ifaceIndir(t *rtype) bool {
return t.kind&kindDirectIface == 0
}
调用实例
func Add(a, b int) int { return a + b }
func main() {
v := reflect.ValueOf(Add)
if v.Kind() != reflect.Func {
return
}
t := v.Type()
argv := make([]reflect.Value, t.NumIn())
for i := range argv {
if t.In(i).Kind() != reflect.Int {
return
}
argv[i] = reflect.ValueOf(i)
}
result := v.Call(argv)
if len(result) != 1 || result[0].Kind() != reflect.Int {
return
}
fmt.Println(result[0].Int()) // #=> 1
}
func (v Value) Call(in []Value) []Value {
v.mustBe(Func)
v.mustBeExported()
return v.call("Call", in)
}
关于零值
// IsZero reports whether v is the zero value for its type.
// It panics if the argument is invalid.
func (v Value) IsZero() bool {
switch v.kind() {
case Bool:
return !v.Bool()
case Int, Int8, Int16, Int32, Int64:
return v.Int() == 0
case Uint, Uint8, Uint16, Uint32, Uint64, Uintptr:
return v.Uint() == 0
case Float32, Float64:
return math.Float64bits(v.Float()) == 0
case Complex64, Complex128:
c := v.Complex()
return math.Float64bits(real(c)) == 0 && math.Float64bits(imag(c)) == 0
case Array:
for i := 0; i < v.Len(); i++ {
if !v.Index(i).IsZero() {
return false
}
}
return true
case Chan, Func, Interface, Map, Ptr, Slice, UnsafePointer:
return v.IsNil()
case String:
return v.Len() == 0
case Struct:
for i := 0; i < v.NumField(); i++ {
if !v.Field(i).IsZero() {
return false
}
}
return true
default:
// This should never happens, but will act as a safeguard for
// later, as a default value doesn't makes sense here.
panic(&ValueError{"reflect.Value.IsZero", v.Kind()})
}
}
// Zero returns a Value representing the zero value for the specified type.
// The result is different from the zero value of the Value struct,
// which represents no value at all.
// For example, Zero(TypeOf(42)) returns a Value with Kind Int and value 0.
// The returned value is neither addressable nor settable.
func Zero(typ Type) Value {
if typ == nil {
panic("reflect: Zero(nil)")
}
t := typ.(*rtype)
fl := flag(t.Kind())
if ifaceIndir(t) {
return Value{t, unsafe_New(t), fl | flagIndir}
}
return Value{t, nil, fl}
}
channel
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
type waitq struct {
first *sudog
last *sudog
}
// sudog represents a g in a wait list, such as for sending/receiving
// on a channel.
//
// sudog is necessary because the g ↔ synchronization object relation
// is many-to-many. A g can be on many wait lists, so there may be
// many sudogs for one g; and many gs may be waiting on the same
// synchronization object, so there may be many sudogs for one object.
//
// sudogs are allocated from a special pool. Use acquireSudog and
// releaseSudog to allocate and free them.
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
isSelect bool
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
运行时
并发编程
- Golang 的 goroutine 是如何实现的? - eahydra的回答
- Golang 的 goroutine 是如何实现的? - 腾讯技术工程的回答
- 6.5 调度器
- 调度原理
- Go的调度模型
- Go的调度循环
- Go的调度触发
- 主动挂起
runtime.gospark() - 系统调用
runtime.Syscallruntime.RawSyscall
- 协作式调度
runtime.Gosched()
- 主动挂起
在了解Go的运行时的scheduler之前,需要先了解为什么需要它,因为我们可能会想,OS内核不是已经有一个线程scheduler了嘛? 熟悉POSIX API的人都知道,POSIX的方案在很大程度上是对Unix process进场模型的一个逻辑描述和扩展,两者有很多相似的地方。 Thread有自己的信号掩码,CPU affinity等。但是很多特征对于Go程序来说都是累赘。 尤其是context上下文切换的耗时。另一个原因是Go的垃圾回收需要所有的goroutine停止,使得内存在一个一致的状态。垃圾回收的时间点是不确定的,如果依靠OS自身的scheduler来调度,那么会有大量的线程需要停止工作。
单独的开发一个GO得调度器,可以是其知道在什么时候内存状态是一致的,也就是说,当开始垃圾回收时,运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是等待所有的线程。
我对goroutine的理解类似于C/C++下常用的线程池技术。但是goroutine要在这基础上大大的前进了好多。首先,go关键字极大的简化了C/C++下往线程池投递任务的操作。虽然C++11引入了lambda,但是因为没有GC的缘故用起来还是稍微蛋疼的。其次就是goroutine的调度器解决了一般线程池常见的问题,就是遇到阻塞或者同步动作时,怎么让线程池更容易扩展,不会因为其中一个任务的阻塞或者同步独占线程,甚至怎么避免由此问题带来的死锁。而在C/C++语言里,想做到这点非常的困难,没有类似Golang的runtime,做起来会非常痛苦。 Golang在这点上做的也是非常的漂亮。发起的同步或者channel动作,哪怕网络操作,都会把自身goroutine切换出去,让下一个预备好的goroutine去运行。而且Golang其本身还在此基础上很容易的做到对线程池的扩展,根据程序行为自动扩展或者收缩线程,尽可能的让线程保持在一个合适的数目。
用户空间线程和内核空间线程之间的映射关系有:N:1,1:1和M:N
- N:1 是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。
- 1:1 是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。
- M:N 是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
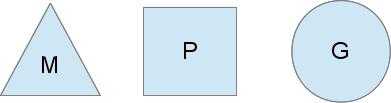
Go的调度器内部有三个重要的结构:M,P,S
- M: 代表真正的内核OS线程,和POSIX里的thread差不多,真正干活的人
- G: 代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
- P: 代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从 N:1 到 N:M 映射的关键。

图中有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。 P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。 图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue), Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个 goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程! 图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所有的context P。M 也可以从其他 M 那里偷一个上下文 P 来运行新的 G。
这三个结构体非常复杂,字段的数量特别多:
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
param unsafe.Pointer // passed parameter on wakeup
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
schedlink guintptr
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
paniconfault bool // panic (instead of crash) on unexpected fault address
preemptscan bool // preempted g does scan for gc
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
gcscanvalid bool // false at start of gc cycle, true if G has not run since last scan; TODO: remove?
throwsplit bool // must not split stack
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr // pc of go statement that created this goroutine
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone uint32 // are we participating in a select and did someone win the race?
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of
// bytes allocated. If this is positive, then the G has credit
// to allocate gcAssistBytes bytes without assisting. If this
// is negative, then the G must correct this by performing
// scan work. We track this in bytes to make it fast to update
// and check for debt in the malloc hot path. The assist ratio
// determines how this corresponds to scan work debt.
gcAssistBytes int64
}
// 这些内容会在调度器保存或者恢复上下文的时候用到,其中的栈指针和程序计数器会用来存储或者恢复寄存器中的值,改变程序即将执行的代码
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr // 栈指针 stack pointer
pc uintptr // 程序计数器 program counter
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}
// A guintptr holds a goroutine pointer, but typed as a uintptr
// to bypass write barriers. It is used in the Gobuf goroutine state
// and in scheduling lists that are manipulated without a P.
//
// The Gobuf.g goroutine pointer is almost always updated by assembly code.
// In one of the few places it is updated by Go code - func save - it must be
// treated as a uintptr to avoid a write barrier being emitted at a bad time.
// Instead of figuring out how to emit the write barriers missing in the
// assembly manipulation, we change the type of the field to uintptr,
// so that it does not require write barriers at all.
//
// Goroutine structs are published in the allg list and never freed.
// That will keep the goroutine structs from being collected.
// There is never a time that Gobuf.g's contain the only references
// to a goroutine: the publishing of the goroutine in allg comes first.
// Goroutine pointers are also kept in non-GC-visible places like TLS,
// so I can't see them ever moving. If we did want to start moving data
// in the GC, we'd need to allocate the goroutine structs from an
// alternate arena. Using guintptr doesn't make that problem any worse.
type guintptr uintptr
type m struct {
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
sigmask sigset // storage for saved signal mask
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
curg *g // current running goroutine 正在运行的 goroutine
caughtsig guintptr // goroutine running during fatal signal
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
id int64
mallocing int32
throwing int32
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
profilehz int32
spinning bool // m is out of work and is actively looking for work
blocked bool // m is blocked on a note
newSigstack bool // minit on C thread called sigaltstack
printlock int8
incgo bool // m is executing a cgo call
freeWait uint32 // if == 0, safe to free g0 and delete m (atomic)
fastrand [2]uint32
needextram bool
traceback uint8
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
park note
alllink *m // on allm
schedlink muintptr // 敲黑板
mcache *mcache
lockedg guintptr
createstack [32]uintptr // stack that created this thread.
lockedExt uint32 // tracking for external LockOSThread
lockedInt uint32 // tracking for internal lockOSThread
nextwaitm muintptr // next m waiting for lock
waitunlockf func(*g, unsafe.Pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
thread uintptr // thread handle
freelink *m // on sched.freem
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
vdsoSP uintptr // SP for traceback while in VDSO call (0 if not in call)
vdsoPC uintptr // PC for traceback while in VDSO call
dlogPerM
mOS
}
// 处理器的运行时表示,调度器的内部实现
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
raceprocctx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
// Available G's (status == Gdead) 敲黑板
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
tracebuf traceBufPtr
// traceSweep indicates the sweep events should be traced.
// This is used to defer the sweep start event until a span
// has actually been swept.
traceSweep bool
// traceSwept and traceReclaimed track the number of bytes
// swept and reclaimed by sweeping in the current sweep loop.
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
_ uint32 // Alignment for atomic fields below
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
gcBgMarkWorker guintptr // (atomic)
gcMarkWorkerMode gcMarkWorkerMode
// gcMarkWorkerStartTime is the nanotime() at which this mark
// worker started.
gcMarkWorkerStartTime int64
// gcw is this P's GC work buffer cache. The work buffer is
// filled by write barriers, drained by mutator assists, and
// disposed on certain GC state transitions.
gcw gcWork
// wbBuf is this P's GC write barrier buffer.
//
// TODO: Consider caching this in the running G.
wbBuf wbBuf
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad cpu.CacheLinePad
}
type schedt struct {
// accessed atomically. keep at top to ensure alignment on 32-bit systems.
goidgen uint64
lastpoll uint64
lock mutex
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be
// sure to call checkdead().
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys uint32 // number of system goroutines; updated atomically
pidle puintptr // idle p's
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
runq gQueue
runqsize int32
// disable controls selective disabling of the scheduler.
//
// Use schedEnableUser to control this.
//
// disable is protected by sched.lock.
disable struct {
// user disables scheduling of user goroutines.
user bool
runnable gQueue // pending runnable Gs
n int32 // length of runnable
}
// Global cache of dead G's. // 敲黑板
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// Central cache of sudog structs.
sudoglock mutex
sudogcache *sudog
// Central pool of available defer structs of different sizes.
deferlock mutex
deferpool [5]*_defer
// freem is the list of m's waiting to be freed when their
// m.exited is set. Linked through m.freelink.
freem *m
gcwaiting uint32 // gc is waiting to run
stopwait int32
stopnote note
sysmonwait uint32
sysmonnote note
// safepointFn should be called on each P at the next GC
// safepoint if p.runSafePointFn is set.
safePointFn func(*p)
safePointWait int32
safePointNote note
profilehz int32 // cpu profiling rate
procresizetime int64 // nanotime() of last change to gomaxprocs
totaltime int64 // ∫gomaxprocs dt up to procresizetime
}
go 关键字的背后过程(编译器会将所有的 go 关键字被转换成 runtime.newproc 函数,该函数会接收参数大小和表示函数的指针 funcval):
// A gList is a list of Gs linked through g.schedlink. A G can only be
// on one gQueue or gList at a time.
type gList struct {
head guintptr
}
// A gQueue is a dequeue of Gs linked through g.schedlink. A G can only
// be on one gQueue or gList at a time.
type gQueue struct {
head guintptr
tail guintptr
}
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
// Cannot split the stack because it assumes that the arguments
// are available sequentially after &fn; they would not be
// copied if a stack split occurred.
//go:nosplit
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}
// getg returns the pointer to the current g.
// The compiler rewrites calls to this function into instructions
// that fetch the g directly (from TLS or from the dedicated register).
func getg() *g
// mcall switches from the g to the g0 stack and invokes fn(g),
// where g is the goroutine that made the call.
// mcall saves g's current PC/SP in g->sched so that it can be restored later.
// It is up to fn to arrange for that later execution, typically by recording
// g in a data structure, causing something to call ready(g) later.
// mcall returns to the original goroutine g later, when g has been rescheduled.
// fn must not return at all; typically it ends by calling schedule, to let the m
// run other goroutines.
//
// mcall can only be called from g stacks (not g0, not gsignal).
//
// This must NOT be go:noescape: if fn is a stack-allocated closure,
// fn puts g on a run queue, and g executes before fn returns, the
// closure will be invalidated while it is still executing.
func mcall(fn func(*g))
// dropg removes the association between m and the current goroutine m->curg (gp for short).
// Typically a caller sets gp's status away from Grunning and then
// immediately calls dropg to finish the job. The caller is also responsible
// for arranging that gp will be restarted using ready at an
// appropriate time. After calling dropg and arranging for gp to be
// readied later, the caller can do other work but eventually should
// call schedule to restart the scheduling of goroutines on this m.
func dropg() {
_g_ := getg()
setMNoWB(&_g_.m.curg.m, nil)
setGNoWB(&_g_.m.curg, nil)
}
// newproc1 会从处理器或者调度器的缓存中获取新的 goroutine 结构体,也可以调用 runtime.malg 函数创建新的结构体
// Create a new g running fn with narg bytes of arguments starting
// at argp. callerpc is the address of the go statement that created
// this. The new g is put on the queue of g's waiting to run.
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
acquirem() // disable preemption because it can be holding p in a local var
siz := narg
siz = (siz + 7) &^ 7
// We could allocate a larger initial stack if necessary.
// Not worth it: this is almost always an error.
// 4*sizeof(uintreg): extra space added below
// sizeof(uintreg): caller's LR (arm) or return address (x86, in gostartcall).
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 {
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
// This is a stack-to-stack copy. If write barriers
// are enabled and the source stack is grey (the
// destination is always black), then perform a
// barrier copy. We do this *after* the memmove
// because the destination stack may have garbage on
// it.
if writeBarrier.needed && !_g_.m.curg.gcscandone {
f := findfunc(fn.fn)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
if stkmap.nbit > 0 {
// We're in the prologue, so it's always stack map index 0.
bv := stackmapdata(stkmap, 0)
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)
}
}
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
newg.gcscanvalid = false
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
runqput(_p_, newg, true)
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
releasem(_g_.m)
}
// Get from gfree list.
// If local list is empty, grab a batch from global list.
// 当处理器的 Goroutine 列表为空时,会将调度器持有的空闲 Goroutine 转移到当前处理器上,直到 gFree 列表中的 Goroutine 数量达到 32;
// 当处理器的 Goroutine 数量充足时,会从列表头部返回一个新的 Goroutine;
func gfget(_p_ *p) *g {
retry:
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
// Move a batch of free Gs to the P.
for _p_.gFree.n < 32 {
// Prefer Gs with stacks.
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
_p_.gFree.push(gp)
_p_.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
gp := _p_.gFree.pop()
if gp == nil {
return nil
}
_p_.gFree.n--
if gp.stack.lo == 0 {
// Stack was deallocated in gfput. Allocate a new one.
systemstack(func() {
gp.stack = stackalloc(_FixedStack)
})
gp.stackguard0 = gp.stack.lo + _StackGuard
} else {
if raceenabled {
racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if msanenabled {
msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
}
return gp
}
// Purge all cached G's from gfree list to the global list.
func gfpurge(_p_ *p) {
lock(&sched.gFree.lock)
for !_p_.gFree.empty() {
gp := _p_.gFree.pop()
_p_.gFree.n--
if gp.stack.lo == 0 {
sched.gFree.noStack.push(gp)
} else {
sched.gFree.stack.push(gp)
}
sched.gFree.n++
}
unlock(&sched.gFree.lock)
}
// Allocate a new g, with a stack big enough for stacksize bytes.
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
stacksize = round2(_StackSystem + stacksize)
systemstack(func() {
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + _StackGuard
newg.stackguard1 = ^uintptr(0)
}
return newg
}
var (
allgs []*g
allglock mutex
)
func allgadd(gp *g) {
if readgstatus(gp) == _Gidle {
throw("allgadd: bad status Gidle")
}
lock(&allglock)
allgs = append(allgs, gp)
allglen = uintptr(len(allgs))
unlock(&allglock)
}

goroutine 运行队列
-
处理器本地的运行队列(
runtime.p.runq [256]gunitptr):是一个使用数组构成的环形链表,它最多可以存储 256 个待执行任务。 -
全局运行队列(
runtime.schedt.runq gQueue):
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the _p_.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(_p_ *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
调度实现
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg()
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
if _g_.m.lockedg != 0 {
stoplockedm()
execute(_g_.m.lockedg.ptr(), false) // Never returns.
}
// We should not schedule away from a g that is executing a cgo call,
// since the cgo call is using the m's g0 stack.
if _g_.m.incgo {
throw("schedule: in cgo")
}
top:
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _g_.m.p.ptr().runSafePointFn != 0 {
runSafePointFn()
}
var gp *g
var inheritTime bool
// Normal goroutines will check for need to wakeP in ready,
// but GCworkers and tracereaders will not, so the check must
// be done here instead.
tryWakeP := false
if trace.enabled || trace.shutdown {
gp = traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
tryWakeP = true
}
}
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
tryWakeP = tryWakeP || gp != nil
}
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
// This thread is going to run a goroutine and is not spinning anymore,
// so if it was marked as spinning we need to reset it now and potentially
// start a new spinning M.
if _g_.m.spinning {
resetspinning()
}
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled. Put it on
// the list of pending runnable goroutines for when we
// re-enable user scheduling and look again.
lock(&sched.lock)
if schedEnabled(gp) {
// Something re-enabled scheduling while we
// were acquiring the lock.
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
// If about to schedule a not-normal goroutine (a GCworker or tracereader),
// wake a P if there is one.
if tryWakeP {
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
}
if gp.lockedm != 0 {
// Hands off own p to the locked m,
// then blocks waiting for a new p.
startlockedm(gp)
goto top
}
execute(gp, inheritTime)
}
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {...}
// Schedules gp to run on the current M.
// If inheritTime is true, gp inherits the remaining time in the
// current time slice. Otherwise, it starts a new time slice.
// Never returns.
//
// Write barriers are allowed because this is called immediately after
// acquiring a P in several places.
//
//go:yeswritebarrierrec
func execute(gp *g, inheritTime bool) {
_g_ := getg()
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
_g_.m.curg = gp
gp.m = _g_.m
// Check whether the profiler needs to be turned on or off.
hz := sched.profilehz
if _g_.m.profilehz != hz {
setThreadCPUProfiler(hz)
}
if trace.enabled {
// GoSysExit has to happen when we have a P, but before GoStart.
// So we emit it here.
if gp.syscallsp != 0 && gp.sysblocktraced {
traceGoSysExit(gp.sysexitticks)
}
traceGoStart()
}
gogo(&gp.sched)
}
内存管理
内存分配

- 图解 TCMalloc - 知乎
- TCMalloc 是 Google 开发的内存分配器,在不少项目中都有使用,例如在 Golang 中就使用了类似的算法进行内存分配。它具有现代化内存分配器的基本特征:对抗内存碎片、在多核处理器能够 scale。据称,它的内存分配速度是 glibc2.3 中实现的 malloc的数倍。
- 用隐式 FreeList 分配定长记录(对象)

- 大小呈非严格倍数式增长的 FreeList 簇:分配变长记录(对多种定长记录的分配)
- PageHeap:对所有的Page进行管理
- Span:大对象的分配。Span 也就是多个连续的 Page 会组成一个 Span,在 Span 中记录起始 Page 的编号,以及 Page 数量。分配对象时,大的对象直接分配 Span,小的对象从 Span 中分配。
- RadixTree:从Page到Span,记录每个Page属于的Span。可以把 RadixTree 理解成压缩过的前缀树(trie),所谓压缩,就是在一条路径上的节点都只有一个子节点,就把这条路径合并到父节点去,因此内部节点最少会有 Radix 个子节点。
- 全局对象分配器 CentralCache:每种规格的对象,都从不同的 Span 进行分配;每种规则的对象都有一个独立的内存分配单元 CentralCache。
- ThreadCache
- 每个线程都一个线程局部的 ThreadCache,按照不同的规格,维护了对象的链表;如果ThreadCache 的对象不够了,就从 CentralCache 进行批量分配;如果 CentralCache 依然没有,就从PageHeap申请Span;如果 PageHeap没有合适的 Page,就只能从操作系统申请了。
- 在释放内存的时候,ThreadCache依然遵循批量释放的策略,对象积累到一定程度就释放给 CentralCache;CentralCache发现一个 Span的内存完全释放了,就可以把这个 Span 归还给 PageHeap;PageHeap发现一批连续的Page都释放了,就可以归还给操作系统。

- ThreadCache
- 层级关系为:object - page -span - ThreadCache - CentalCache - OS
- TCMalloc 是 Google 开发的内存分配器,在不少项目中都有使用,例如在 Golang 中就使用了类似的算法进行内存分配。它具有现代化内存分配器的基本特征:对抗内存碎片、在多核处理器能够 scale。据称,它的内存分配速度是 glibc2.3 中实现的 malloc的数倍。

内存结构
Go 1.10 以前分为 spans, bitmap, arena 三个区域:arena区域划分成一个个的page,每个 8KB;spans区域存放指向 span 的指针;bitmap 主要用于 GC,用两个 bit 表示 arena 中一个字的可用状态。
Go 1.11 及以后版本,改成了两阶系数索引的方式,内存可以超过 512G,可以允许不连续的内存。
mspan
使用span机制来减少碎片. 每个span至少分配1个page(8KB), 划分成固定大小的slot, 用于分配一定大小范围的内存需求。
分配策略

- 不同的分配器
- tiny 分配器:用于小于 maxTinySize (16B)无指针对象的内存分配。
- fixalloc:用于分配rutime中固定大小的一些结构。每次请求对应结构体大小,释放时放在list链表中。
- stackcache:每个 P 都有,用于分配 goroutine 的 stack。和普通对象内存一样,也有多个层级。
GC


当前 Go 的 GC 特征
- 三色标记
- 并发标记和清扫
- 非分代
- 非紧缩
- 混合写屏障


进阶知识
元编程
插件系统
Go 语言的插件系统基于 C 语言动态库实现的,所以它也继承了 C 语言动态库的优点和缺点。
Linux 中的静态库(Static Library)和动态库(Dynamic Library):
- 静态库或者静态链接库是由编译期决定的程序、外部函数和变量构成的,编译器或者链接器会将程序和变量等内容拷贝到目标的应用并生成一个独立的可执行对象文件
- 动态库或者共享对象可以在多个可执行文件之间共享,程序使用的模块会在运行时从共享对象中加载,而不是在编译程序时打包成独立的可执行文件
代码生成
图灵完备的一个重要特性是计算机程序可以生成另一个程序。
元编程(Metaprogramming)是计算机编程中一个非常重要、也很有趣的概念,维基百科上将元编程描述成一种计算机程序可以将代码看待成数据的能力。
Go 语言的代码生成机制会读取包含预编译指令的注释,然后执行注释中的命令读取包中的文件,它们将文件解析成抽象语法树并根据语法树生成新的 Go 语言代码和文件,生成的代码会在项目的编译期间与其他代码一起编译和运行。
//go:generate command argument...
go generate 不会被 go build 等命令自动执行,该命令需要显式的触发,手动执行该命令时会在文件中扫描上述形式的注释并执行后面的执行命令,需要注意的是 go:generate 和前面的 // 之间没有空格,这种不包含空格的注释一般是 Go 语言的编译器指令,而我们在代码中的正常注释都应该保留这个空格。
标准库
JSON
接口
在 JSON 序列化和反序列化的过程中,它们会使用反射判断结构体类型是否实现了下面的接口,如果实现了上述接口就会优先使用对应的方法进行编码和解码操作。
type Marshaler interface {
MarshalJSON() ([]byte, error)
}
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
type TextMarshaler interface {
MarshalText() (text []byte, err error)
}
type TextUnmarshaler interface {
UnmarshalText(text []byte) error
}
标签
- 使用标签这一特性直接建立键与字段之间的映射关系
- JSON 中的标签由两部分组成,标签名和后面的标签选项,即
encoding/json.tagOptions,标签名和字段名会建立一一对应的关系,后面的标签选项也会影响编解码的过程 - Well known struct tags · golang/go Wiki
- 自定义Go Json的序列化方法实例
type S struct {
F0 string `alias:"field_0"`
F1 string `alias:""`
F2 string
}
s := S{}
st := reflect.TypeOf(s)
for i := 0; i < st.NumField(); i++ {
field := st.Field(i)
if alias, ok := field.Tag.Lookup("alias"); ok {
if alias == "" {
fmt.Println("(blank)")
} else {
fmt.Println(alias)
}
} else {
fmt.Println("(not specified)")
}
}
/* output:
field_0
(blank)
(not specified)
*/
看懂Go的汇编代码
-
GOOS=linux GOARCH=amd64 go tool compile -S x.gogo build -gcflags -S x.gogo build -o x.exe x.go; go tool objdump -s main.main x.exe查看某个函数的汇编代码- The
FUNCDATAandPCDATAdirectives contain information for use by the garbage collector; they are introduced by the compiler. - 伪寄存器
FP: Frame pointer: arguments and locals.PC: Program counter: jumps and branches.SB: Static base pointer: global symbols.SP: Stack pointer: top of stack.
- The
SBpseudo-register can be thought of as the origin of memory.foo(SB),foo<>(SB),foo+4(SB). - The
FPpseudo-register is a virtual frame pointer used to refer to function arguments.0(FP),8(FP),first_arg+0(FP) - The
SPpseudo-register is a virtual stack pointer used to refer to frame-local variables and the arguments being prepared for function calls.x-8(SP),y-4(SP). - Instructions, registers, and assembler directives are always in UPPER CASE to remind you that assembly programming is a fraught endeavor.
- Directives
- The assembler uses various directives to bind text and data to symbol names.
TEXT,RET,NOSPLIT- The frame size
$24-8states that the function has a 24-byte frame and is called with 8 bytes of argument, which live on the caller’s frame. DATA,GLOBL- arguments to the directives
NOPROFDUPOKNOSPLITRODATANOPTRWRAPPERNEEDCTXT
-
https://stackoverflow.com/questions/23789951/easy-to-read-golang-assembly-output
-
gc:Go compiler
-
gccgo: a new frontend for GCC, the widely used GNU compiler
- https://golang.org/doc/install/gccgo
- CFLAGS, CPPFLAGS, CXXFLAGS, FFLAGS and LDFLAGS may be defined with pseudo #cgo directives within these comments to tweak the behavior of the C, C++ or Fortran compiler.
-
cgo
- https://blog.golang.org/cgo
- https://golang.org/cmd/cgo/
- Go code may not store a Go pointer in C memory. C code may store Go pointers in C memory, subject to the rule above: it must stop storing the Go pointer when the C function returns.
- why cgo?
-
- 在数字电路中,用来存放二进制数据或代码的电路称为寄存器。寄存器是由具有存储功能的触发器组合起来构成的。一个触发器可以存储1位二进制代码,存放多位二进制代码的寄存器需用逐个触发器来构成。对寄存器中的触发器只要求它们具有置1,置0的功能即可,因而无论是用电平触发的触发器,还是用脉冲触发或边沿触发的触发器,都可以组成寄存器。8086有8个16比特的寄存器,包括栈寄存器SP与BP,但不包括指令寄存器IP、控制寄存器FLAGS以及四个段寄存器。AX, BX, CX, DX,这四个寄存器可以按照字节访问;但BP, SI, DI, SP,这四个地址寄存器只能按照16位宽访问。
- 通用寄存器组包括AX、BX、CX、DX4个16位寄存器,用以存放16位数据或地址。也可用作8位寄存器。用作8位寄存器时分别记为AH、AL、BH、BL、CH、CL、DH、DL。只能存放8位数据,不能存放地址。它们分别是AX、BX、CX、DX的高八位和低八位。若AX=1234H,则AH=12H,AL=34H。通用寄存器通用性强,对任何指令,它们具有相同的功能。为了缩短指令代码的长度,在8086中,某些通用寄存器用作专门用途。
- AX(AH、AL):累加器。有些指令约定以AX(或AL)为源或目的寄存器。输入/输出指令必须通过AX或AL实现,例如:端口地址为43H的内容读入CPU的指令为INAL,43H或INAX,43H。目的操作数只能是AL/AX,而不能是其他的寄存器。
- BX(BH、BL):基址寄存器。BX可用作间接寻址的地址寄存器和基地址寄存器,BH、BL可用作8位通用数据寄存器。
- CX(CH、CL):计数寄存器。CX在循环和串操作中充当计数器,指令执行后CX内容自动修改,因此称为计数寄存器。
- DX(DH、DL):数据寄存器。除用作通用寄存器外,在I/O指令中可用作端口地址寄存器,乘除指令中用作辅助累加器。
- 指针和变址寄存器
- BP( Base Pointer regilter):基址指针寄存器。SP指向栈顶元素地址,有自加和自减度能力,而BP没有。但是BP可以定位栈中某个元素的物理地址,在特殊时候起辅助作用,只有在寻找栈里的数据和使用个别的寻址方式时候才能用到。例如,堆栈中压入了很多数据或者地址,你肯定想通过SP来访问这些数据或者地址,但SP是要指向栈顶的,是不能随便乱改的,这时候你就需要使用BP,把SP的值传递给BP,通过BP来寻找堆栈里数据或者地址。
- SP( Stack Pointer Register):栈指针寄存器。 指向栈顶地址,与SS相配合使用。
- SI( Source Index register):源变址寄存器。 一般情况下与DS联用,来确定某个储存单元的地址。
- DI( Destination Index Register):目的变址寄存器。一般情况下与DS联用,来确定某个储存单元的地址。
- 这四个寄存器,都是16位的,不可以分割为八位。
- BP 和 SP 有扩展版的 EBP 和 ESP。
- 段寄存器
- 8086/8088 CPU内部设置了4个16位段寄存器,由它们给出相应逻辑段的首地址,称为“段基址”。段基址与段内偏移地址组合形成20位物理地址,段内偏移地址可以存放在寄存器中,也可以存放在存储器中。
- 代码段寄存器CS(.text)、数据段寄存器DS(.data)、堆栈段寄存器SS(.stack)、附加段寄存器ES(.extra)
- 代码段内存放可执行的指令代码,数据段和附加段内存放操作的数据,通常操作数在数据段中,而在串指令中,目的操作数指明必须在附加段中。堆栈段开辟为程序执行中所要用的堆栈区。
- 指令指针寄存器 IP
- 16位指令指针寄存器IP,用来存放将要执行的下一条指令在现行代码段中的偏移地址。
- 程序运行中,它由BIU自动修改,使IP始终指向下一条将要执行的指令的地址,因此它是用来控制指令序列的执行流程的,是一个重要的寄存器。8086程序不能直接访问IP,但可以通过某些指令修改IP的内容。例如,当遇到中断指令或调用子程序指令时,8086自动调整IP的内容,将IP中下一条将要执行的指令地址偏移量人栈保护,待中断程序执行完毕或子程序返回时,可将保护的内容从堆栈中弹出到IP,使主程序继续运行。在跳转指令时,则将新的跳转目标地址送入IP,改变它的内容,实现了程序的转移。
- 标志寄存器FR (flags register)
- 程序状态字寄存器
- FR是16位寄存器,其中有9位有效位用来存放状态标志和控制标志。状态标志共6位,CF、PF、AF、ZF、SF和OF,用于寄存程序运行的状态信息,这些标志往往用作后续指令判断的依据。控制标志有3位,IF、DF和TF,用于控制CPU的操作,是人为设置的。
-
虚拟内存分段
- https://en.wikipedia.org/wiki/Flat_memory_model
- Flat memory model
- Paged memory model
- X86 segmented memory model
- https://en.wikipedia.org/wiki/Memory_segmentation#x86_architecture
- https://en.wikipedia.org/wiki/X86_memory_segmentation
- Four of the segment registers: CS, SS, DS, and ES are forced to 0, and the limit to 2^64.
- The 80386 also introduced two new general-purpose data segment registers, FS and GS, to the original set of four segment registers (CS, DS, ES, and SS). The segment registers FS and GS can still have a nonzero base address.

- https://stackoverflow.com/questions/18934894/memory-map-shows-more-ram-than-physically-available
- 物理地址:这四个地址中,最容易理解的就是物理地址了,在实地址模式下,程序员操作的就是物理地址,顾名思义,所谓的物理地址就是物理内存上的32位地址,通过物理地址可以直接定位到物理内存上的位置,无论任何操作,最终都必须要得到物理地址才能在物理内存上进行操作。 在实地址模式下并没有另外的三个概念,所以要说到另外的三个地址,就不得不说说分段和分页机制。
- 虚拟地址:所谓的虚拟地址,从广义上讲,就是相对于物理地址的概念,也就是说,不是物理的就是虚拟的,因为不是物理地址的地址是无法在物理内存上定位的,所以他们都可以被称为“虚拟地址”,也就是说,从这个意义上讲,逻辑地址和线性地址都可以被称为虚拟地址,而从狭义上讲,虚拟地址指的是没有经过分页机制和分段机制转换的地址,也就是段寄存器和变址寄存器内容的组合,从这个意义上来说,虚拟地址就是类似于CS:SI这样形式的地址。
- 逻辑地址:逻辑地址就是上层程序员可以操作的地址,也就是变址寄存器中存储的 32 位偏移地址,而其他寄存器上的地址往往对于上层程序员来说是不可更改甚至是不可见的。
- 线性地址:对狭义上的虚拟地址通过分段机制以后,可以得到段基址、段界限以及段偏移地址(即逻辑地址),段基址与段偏移地址的组合就是线性地址,线性地址可以在虚拟内存上完成定位,所以也是程序员最关心的地址,线性地址通过 MMU(内存管理单元)利用分页机制进行转换以后就可以得到实际的物理地址了,对于程序员来说,他们并不关注 MMU 如何工作以及其得到的结果,因为了解所操作的内存究竟在哪个页框中是没有什么意义的,所以他们只需要关心线性地址或者逻辑地址就可以完成全部工作了。
- 虚拟内存的那点事儿

- 蓝色是未使用的内存空间
- 文本段(Text):也称为代码段。进程启动时会将程序的代码加载到物理内存中,文本段映射到这片物理内存。
- 初始化数据(Data):包含程序显式初始化的全局变量和静态变量,这些数据是在程序真正运行前就已经确定的数据,所以可以提前加载到内存保存好。
- 未初始化数据(BSS):未初始化的全局变量和静态变量,这些变量的值是在程序真正运行起来并为其赋值后才能确定的,所以程序加载之初,只需要记录它的内存地址和所需大小。出于历史原因,这段空间也称为BSS段。
- 栈(Stack):是一个可以动态增长和收缩的内存段落,由栈帧(Stack Frames)组成,进程每调用一次函数,都将为该函数分配一个栈帧,栈帧中保存了该函数的局部变量、参数值和返回值。注意,编译器会将函数参数放入寄存器来优化程序,只有寄存器放不下的参数才使用栈帧来保存。
- 堆(Heap):程序运行时,变量的值以及动态请求分配的内存都在这个内存段落中。
- 内核段(Kernel):这部分是操作系统内核运行时所占用内存在各进程虚拟地址空间中的映射。所有进程都有,且映射地址相同,因为都映射到内核使用的内存。这段内存只有内核能访问,用户进程无法访问到该段落。
- https://en.wikipedia.org/wiki/Flat_memory_model
-
opcodes
End